A group of Microsoft engineers have built an artificial intelligence technique called deep neural networks that will be deployed on Catapult by the end of 2016 to power Bing search results. They say that this AI supercomputer in the cloud will increase the speed and efficiency of Microsoft’s data centers and that their will be a noticeable difference obvious to Bing search engine users. They say that this is the "The slow but eventual end of Moore’s Law."
"Utilizing the FPGA chips, Microsoft engineering (Sitaram Lanka and Derek Chiou) teams can write their algorithms directly onto the hardware they are using, instead of using potentially less efficient software as the middle man," notes Microsoft blogger Allison Linn. "What’s more, an FPGA can be reprogrammed at a moment’s notice to respond to new advances in artificial intelligence or meet another type of unexpected need in a datacenter."
The team created this system that uses a reprogrammable computer chip called a field programmable gate array (FPGA) that will significantly improve the speed of Bing and Azure queries. "This was a moonshot project that succeeded," said Lanka.
What they did was insert an FPGA directly between the network and the servers, which in bypassing the traditional software approach speeds up computation. “What we’ve done now is we’ve made the FPGA the front door,” said Derek Chiou, one of the Microsoft engineers who created the system. "“I think a lot of people don’t know what FPGAs are capable of."
Here is how the team described the technology:
Hyperscale datacenter providers have struggled to balance the growing need for specialized hardware (efficiency) with the economic benefits of homogeneity (manageability). In this paper we propose a new cloud architecture that uses reconfigurable logic to accelerate both network plane functions and applications. This Configurable Cloud architecture places a layer of reconfigurable logic (FPGAs) between the network switches and the servers, enabling network flows to be programmably transformed at line rate, enabling acceleration of local applications running on the server, and enabling the FPGAs to communicate directly, at datacenter scale, to harvest remote FPGAs unused by their local servers.
We deployed this design over a production server bed, and show how it can be used for both service acceleration (Web search ranking) and network acceleration (encryption of data in transit at high speeds).

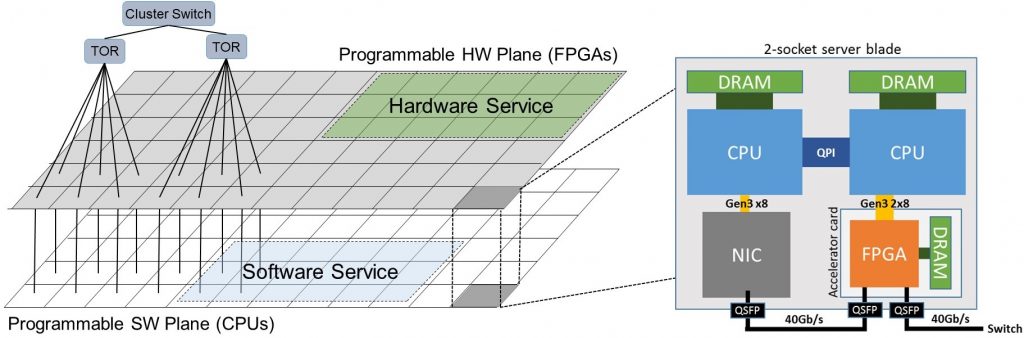
This architecture is much more scalable than prior work which used secondary rack-scale networks for inter-FPGA communication. By coupling to the network plane, direct FPGA-to-FPGA messages can be achieved at comparable latency to previous work, without the secondary network. Additionally, the scale of direct inter-FPGA messaging is much larger. The average round-trip latencies observed in our measurements among 24, 1000, and 250,000 machines are under 3, 9, and 20 microseconds, respectively. The Configurable Cloud architecture has been deployed at hyperscale in Microsoft’s production datacenters worldwide.